Begging
When you try to implement a machine learning or expect the stock price for the future, have you ever thought you didn't have enough data for your experiment? Let's study how to gather the information you want on the internet by scraping.
In this article, we can get some images from a Japanese website. If you use the images that you get by scrapping for your business or website, your deeds might be illegal. You should be careful about using web scrapping and need to take full responsibility for your actions.
Get an image on a page
environment
・Python 3.6.0
Step
- Access an URL by python
- Get HTML of the page
- Extract src from HTML
- Save the image
※You should not access the page you try to access many times, otherwise, the server will be oppressed.
1. Access an URL by python
We use urllib.request, which is a library for access to a URL.
import urllib.request
html = urllib.request.urlopen('https://beauty.hotpepper.jp/slnH000218616/style/L002266500.html?cstt=1')
print(html)
This action means you just access the URL, which means you don't see HTML. Just return the values people can not read.
2. Get HTML of the page
bs4 is a library for converting into the text people can read.
If you don't have bs4, Let's run this code pip install beautifulsoup4.
import urllib.request
import bs4
html = urllib.request.urlopen('https://beauty.hotpepper.jp/slnH000218616/style/L002266500.html?cstt=1')
soup = bs4.BeautifulSoup(html, 'html.parser')
print(soup)
You can receive HTML by above code. bs4 is more popular so far than pyQuery
3. Extract src from HTML
You should need to understand the structure of HTML.
photos = soup.select("div.pr img.bdImgGray")
paths = list(map(lambda path: path.get('src'), photos))
print(paths)
If you are interested in other ways to get HTML. You can read this article even though this article is written in Japanese.
4. Save the image
You can change the file name whatever you want.
from urllib.request
fileName = 'bijo.jpg'
urllib.request.urlretrieve(paths[0], fileName)
You can get the picture of a girl.
So far
Here is the code so far.
import urllib.request
import bs4
html = urllib.request.urlopen('https://beauty.hotpepper.jp/slnH000218616/style/L002266500.html?cstt=1')
soup = bs4.BeautifulSoup(html, 'html.parser')
photos = soup.select("div.pr img.bdImgGray")
paths = list(map(lambda path: path.get('src'), photos))
fileName = 'bijo.jpg'
urllib.request.urlretrieve(paths[0], fileName)
Access some URLs and get an image per a page automatically
Step
- Make sure the structure of the website you want to be scrapping
- Get HTML
- Save the URL list from HTML to a text file
- Loop step 3
- Extract info you want to get from the text file you create in step 4
1. Make sure the structure of the website you want to be scrapping
If you want to get those images under this category.
https://beauty.hotpepper.jp/catalog/ladys/lenHL03/
You might notice the features of the structure.
https://beauty.hotpepper.jp/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL03&pn=2
・lengthCd=HL03 is category for hair style
・pn=2 means page nation
・pn=100 is last page
So, if you change pn=n of URL, you can get images of those pages.
2. Get HTML
You can get HTML by the way we learned above.
import urllib.request
import bs4
html = urllib.request.urlopen('https://beauty.hotpepper.jp/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL03&pn=1')
soup = bs4.BeautifulSoup(html, 'html.parser')
print(soup)
3. Save the URL list from HTML to a text file
Save each URL into the text file that is named hotpepper_page_urls.txt.
from itertools import chain
columns = soup.find_all('li', class_='dibBL')
atags = map(lambda column: column.find_all('a', class_='pr'), columns)
with open('hotpepper_page_urls.txt', 'w') as f:
for _ in chain.from_iterable(atags):
path = _.get('href')
if not path.startswith('https'): # Relative path
path = '{}{}'.format(base_url, path)
f.write('{}\n'.format(path))
4. Loop step 3
I recommend using the sleep function for suppressing the server load.
import bs4
import urllib.request
from itertools import chain
import time
import random
for page in range(1, 4):
html = urllib.request.urlopen('https://beauty.hotpepper.jp/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL03&pn='+str(page))
soup = bs4.BeautifulSoup(html, 'html.parser')
columns = soup.find_all('li', class_='dibBL')
atags = map(lambda column: column.find_all('a', class_='pr'), columns)
with open('hotpepper_page_urls.txt', 'w') as f:
for _ in chain.from_iterable(atags):
path = _.get('href')
if not path.startswith('https'): # Relative path
path = '{}{}'.format(base_url, path)
f.write('{}\n'.format(path))
time.sleep(1 + random.randint(0, 2)) # to reduce server load
5. Extract info you want to get from the text file you create in step 4
You should change dirpath, which is a directory for saving the pictures
with open('hotpepper_page_urls.txt') as f:
dirpath = '/Users/{name}/Desktop'
num = 1
for url in f:
html = urllib.request.urlopen(url.strip())
soup = bs4.BeautifulSoup(html, 'html.parser')
photos = soup.select("div.pr img.bdImgGray")
paths = map(lambda path: path.get('src'), photos)
for path in paths:
filepath = '{}/{}'.format(dirpath, str(num)+'.jpg')
urllib.request.urlretrieve(path, filepath)
num = num +1
time.sleep(1 + random.randint(0, 2))
Finally
You can get a bunch of images of beautiful women like this.
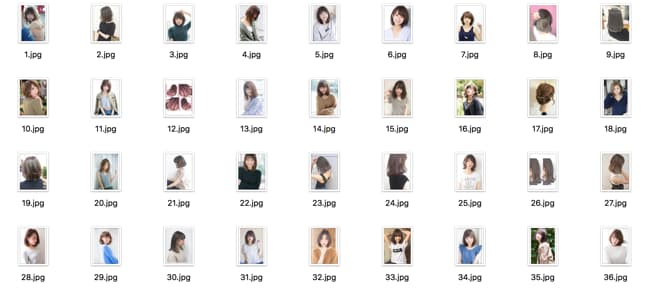
Finally, the code is following.
# -*- coding:utf-8 -*-
import os
import bs4
import time
import random
import urllib.request
from itertools import chain
base_url = 'https://beauty.hotpepper.jp'
def fetch_page_urls(int, page):
page_path = '/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL0'+str(int)+'&pn='+str(page)
html = urllib.request.urlopen('{}{}'.format(base_url, page_path))
soup = bs4.BeautifulSoup(html, 'html.parser')
columns = soup.find_all('li', class_='dibBL')
atags = map(lambda column: column.find_all('a', class_='pr'), columns)
with open('hotpepper_page_urls_type'+str(int)+'.txt', 'w') as f:
for _ in chain.from_iterable(atags):
path = _.get('href')
if not path.startswith('https'): # Relative path
path = '{}{}'.format(base_url, path)
if path[-1] == '/': # Normalize
path = path[:-1]
f.write('{}\n'.format(path))
def fetch_photos(int, page):
with open('hotpepper_page_urls_type'+str(int)+'.txt') as f:
# Make directories for saving images
dirpath = 'photos/hotpepper/lenHL0'+str(int)+'/'+str(page)
# make sure if the file exists
if os.path.isfile('{}/{}'.format(dirpath, '40.jpg')) == True:
print('already got a image')
return False
# make sure if the directory exists
if os.path.isdir(dirpath) == False:
os.makedirs(dirpath)
num = 1
#get URL for the image
for url in f:
html = urllib.request.urlopen(url.strip())
soup = bs4.BeautifulSoup(html, 'html.parser')
photos = soup.select("div.pr img.bdImgGray")
# photos = soup.find_all('div', class_='fl')
paths = map(lambda path: path.get('src'), photos)
#Save the image to directory
for path in paths:
filepath = '{}/{}'.format(dirpath, str(num)+'.jpg')
# Download image file
urllib.request.urlretrieve(path, filepath)
num = num +1
# Add random waiting time (4 - 6 sec)
time.sleep(1 + random.randint(0, 2))
if __name__ == '__main__':
for type in range(5, 6):
for page in range(1, 101):
print('type='+str(type)+'&page='+str(page))
fetch_page_urls(type, page)
fetch_photos(type, page)
Note
Some websites don't allow to do web scraping, so you should make sure whether the site can do or not. And, if you access a website a lot, you might be banned to access by the owner of the site.


