はじめに
株価予測や画像分類などには元データが必要ですが、そもそもデータがなくて分析できないってことがありませんか?
ということで、今回はwebに落ちているデータを取得する「スクレイピング」をしたいと思います。
作業していると楽しくなるといいので、お題はホットペッパービューティーから画像を抜き出してみましょう。
ちなみにダウンロードした画像を商用利用したり、勝手にHPに掲載したりすると違法になることがあります。その他の利用方法に関しては自己責任でお願いします。
ページにアクセスして1枚の画像を保存する
環境
・Python 3.6.0
手順
- PythonでURLにアクセスする
- HTMLを取得する
- srcのURLを抽出する
- 画像を保存する
※他サイトのサーバーに負荷をかけないためにも、ループしまくることはやめましょう。
1. PythonでURLにアクセスする
urllib.request はURL開くための通信周りをいろいろやってくれる便利ライブラリ
import urllib.request
html = urllib.request.urlopen('https://beauty.hotpepper.jp/slnH000218616/style/L002266500.html?cstt=1')
print(html)
アクセスしているだけでHTMLはまだ取得してない。人間には読めない値で返ってくるよ。
2. HTMLを取得する
bs4 はアクセスしたファイルを人間が読みやすいように加工する便利ライブラリ
bs4 をimportしていないなら pip install beautifulsoup4 でインストール
import urllib.request
import bs4
html = urllib.request.urlopen('https://beauty.hotpepper.jp/slnH000218616/style/L002266500.html?cstt=1')
soup = bs4.BeautifulSoup(html, 'html.parser')
print(soup)
HTML、人間が読める言語で返ってきます。
bs4 以外に pyQuery とかあるけど最近は bs4 をよく使うらしい。なんかいいらしい。
3. srcのURLを抽出する
HTML構造を理解する必要がありますね。
photos = soup.select("div.pr img.bdImgGray")
paths = list(map(lambda path: path.get('src'), photos))
print(paths)
他の取得の方法も色々あるから調べてちょ 詳細
4. 画像を保存する
fileNameは自らのファイル構成に変更してください。
from urllib.request
fileName = 'bijo.jpg'
urllib.request.urlretrieve(paths[0], fileName)
Desktopに可愛い子の写真ができたと思います。
完成形
これまでのコードを整理すると以下です。
import urllib.request
import bs4
html = urllib.request.urlopen('https://beauty.hotpepper.jp/slnH000218616/style/L002266500.html?cstt=1')
soup = bs4.BeautifulSoup(html, 'html.parser')
photos = soup.select("div.pr img.bdImgGray")
paths = list(map(lambda path: path.get('src'), photos))
fileName = 'bijo.jpg'
urllib.request.urlretrieve(paths[0], fileName)
複数のURLにアクセスしてページ毎に画像を保存する
手順
- 取得したいサイトのURL構造を理解する。
- HTMLを取得
- 2から必要なURLを抽出してテキストに保存する
- 3をループさせる
- 4で取得したURLリストにアクセスして必要な情報を抽出する
1. 取得したいサイトのURL構造を理解する
このカテゴリに属する写真が欲しいとする。
https://beauty.hotpepper.jp/catalog/ladys/lenHL03/
よく調査すると以下の傾向にあることに気づく。
https://beauty.hotpepper.jp/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL03&pn=2
lengthCd=HL03 でミディアムヘアのカテゴリ選択
pn=2 でページ
pn=100 で最後。101ページ目はない。
ってこと pn=2 を1~100まで変更していけば一覧ページが取れる。
2. HTMLを取得
これまで同様にHTMLを取得。
import urllib.request
import bs4
html = urllib.request.urlopen('https://beauty.hotpepper.jp/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL03&pn=1')
soup = bs4.BeautifulSoup(html, 'html.parser')
print(soup)
3. 2から必要なURLを抽出してテキストに保存する
各ページのURLを hotpepper_page_urls.txt に保存します。
from itertools import chain
columns = soup.find_all('li', class_='dibBL')
atags = map(lambda column: column.find_all('a', class_='pr'), columns)
with open('hotpepper_page_urls.txt', 'w') as f:
for _ in chain.from_iterable(atags):
path = _.get('href')
if not path.startswith('https'): # Relative path
path = '{}{}'.format(base_url, path)
f.write('{}\n'.format(path))
4. 3をループさせる
アクセス負荷を抑えるために必ずsleepをおこないましょう。
import bs4
import urllib.request
from itertools import chain
import time
import random
for page in range(1, 4):
html = urllib.request.urlopen('https://beauty.hotpepper.jp/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL03&pn='+str(page))
soup = bs4.BeautifulSoup(html, 'html.parser')
columns = soup.find_all('li', class_='dibBL')
atags = map(lambda column: column.find_all('a', class_='pr'), columns)
with open('hotpepper_page_urls.txt', 'w') as f:
for _ in chain.from_iterable(atags):
path = _.get('href')
if not path.startswith('https'): # Relative path
path = '{}{}'.format(base_url, path)
f.write('{}\n'.format(path))
time.sleep(1 + random.randint(0, 2)) # 負荷を抑えるために数秒間止める
5. 4で取得したURLリストにアクセスして必要な情報を抽出する
dirpath は自分の保存先に変更してください。
with open('hotpepper_page_urls.txt') as f:
dirpath = '/Users/{name}/Desktop'
num = 1
#画像パスを取得
for url in f:
html = urllib.request.urlopen(url.strip())
soup = bs4.BeautifulSoup(html, 'html.parser')
photos = soup.select("div.pr img.bdImgGray")
paths = map(lambda path: path.get('src'), photos)
#フォルダ保存
for path in paths:
filepath = '{}/{}'.format(dirpath, str(num)+'.jpg')
urllib.request.urlretrieve(path, filepath)
num = num +1
time.sleep(1 + random.randint(0, 2))
最後に
すべてうまくやると、こんな感じに幸せな気分になります。
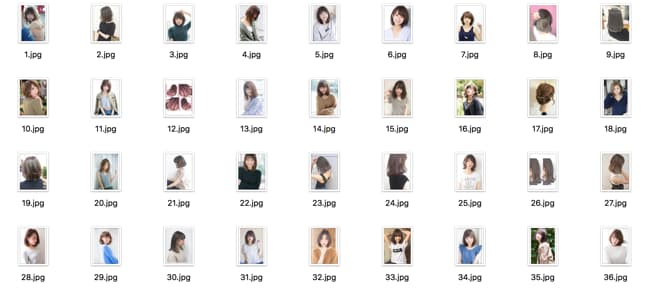
関数化やファイルの存在有無のその他もろもろすればこんな感じになるはず。
# -*- coding:utf-8 -*-
import os
import bs4
import time
import random
import urllib.request
from itertools import chain
base_url = 'https://beauty.hotpepper.jp'
def fetch_page_urls(int, page):
page_path = '/CSP/bt/hairCatalogSearch/ladys/condtion/?lengthCd=HL0'+str(int)+'&pn='+str(page)
html = urllib.request.urlopen('{}{}'.format(base_url, page_path))
soup = bs4.BeautifulSoup(html, 'html.parser')
columns = soup.find_all('li', class_='dibBL')
atags = map(lambda column: column.find_all('a', class_='pr'), columns)
with open('hotpepper_page_urls_type'+str(int)+'.txt', 'w') as f:
for _ in chain.from_iterable(atags):
path = _.get('href')
if not path.startswith('https'): # Relative path
path = '{}{}'.format(base_url, path)
if path[-1] == '/': # Normalize
path = path[:-1]
f.write('{}\n'.format(path))
def fetch_photos(int, page):
with open('hotpepper_page_urls_type'+str(int)+'.txt') as f:
# Make directories for saving images
dirpath = 'photos/hotpepper/lenHL0'+str(int)+'/'+str(page)
# ファイルの存在確認
if os.path.isfile('{}/{}'.format(dirpath, '40.jpg')) == True:
print('すでに取得済')
return False
# ディレクトリの存在確認
if os.path.isdir(dirpath) == False:
os.makedirs(dirpath)
num = 1
#imgのURLを取得
for url in f:
html = urllib.request.urlopen(url.strip())
soup = bs4.BeautifulSoup(html, 'html.parser')
photos = soup.select("div.pr img.bdImgGray")
# photos = soup.find_all('div', class_='fl')
paths = map(lambda path: path.get('src'), photos)
#フォルダ保存
for path in paths:
filepath = '{}/{}'.format(dirpath, str(num)+'.jpg')
# Download image file
urllib.request.urlretrieve(path, filepath)
num = num +1
# Add random waiting time (4 - 6 sec)
time.sleep(1 + random.randint(0, 2))
if __name__ == '__main__':
for type in range(5, 6):
for page in range(1, 101):
print('type='+str(type)+'&page='+str(page))
fetch_page_urls(type, page)
fetch_photos(type, page)
補足
Yahoo!株価はスクレイピング禁止なんで気をつけてね。
アクセスしすぎるとIPアドレスでバンされるから気をつけてね。




